python爬虫入门
学了一下爬虫,感觉云玩家和自己上手还是有去别的
真的看看简单,做起来就有点难了
注意
爬虫首先我们要分析它的合法性:当然大部分情况下是合法的
毕竟搜索引擎就是最大的爬虫啊
但是,如果遇到网站上有明确说明的,例如淘宝,那就最好不要去爬了吧,而且淘宝对于爬虫还是有限制的。
1 | www.taobao.com/robots.txt |
在网站后面加 /robots.txt 就可以知道网站会禁止你爬什么内容。上面的网址就说明了淘宝对于各大爬虫的限制
库安装
首先爬虫需要正则表达式和网页分析,因此我们需要导入两个库
1 | import requests |
但是requests需要自己导入。
我是在windows上面操作的,因此这里只讲windows上面的步骤:
1、管理员方式 打开cmd, ( Win+R 输入cmd)
2、输入命令行:python -m pip install –upgrade pip (这个是升级pip,如果你的pip已经是最高级请跳过)
3、输入命令行:pip install requests
然后你就可以看到安装好的界面了
过程分析
首先我们要爬取一个网页,那么我们就需要一个网址,因为我比较喜欢看小说,因此就选择了一个小说网站来爬:
https://www.biquge5.com/25_25502/ (我选择的是笔趣阁)
我们需要对这个网站进行分析:(鼠标右键 - > 查看网页源代码)
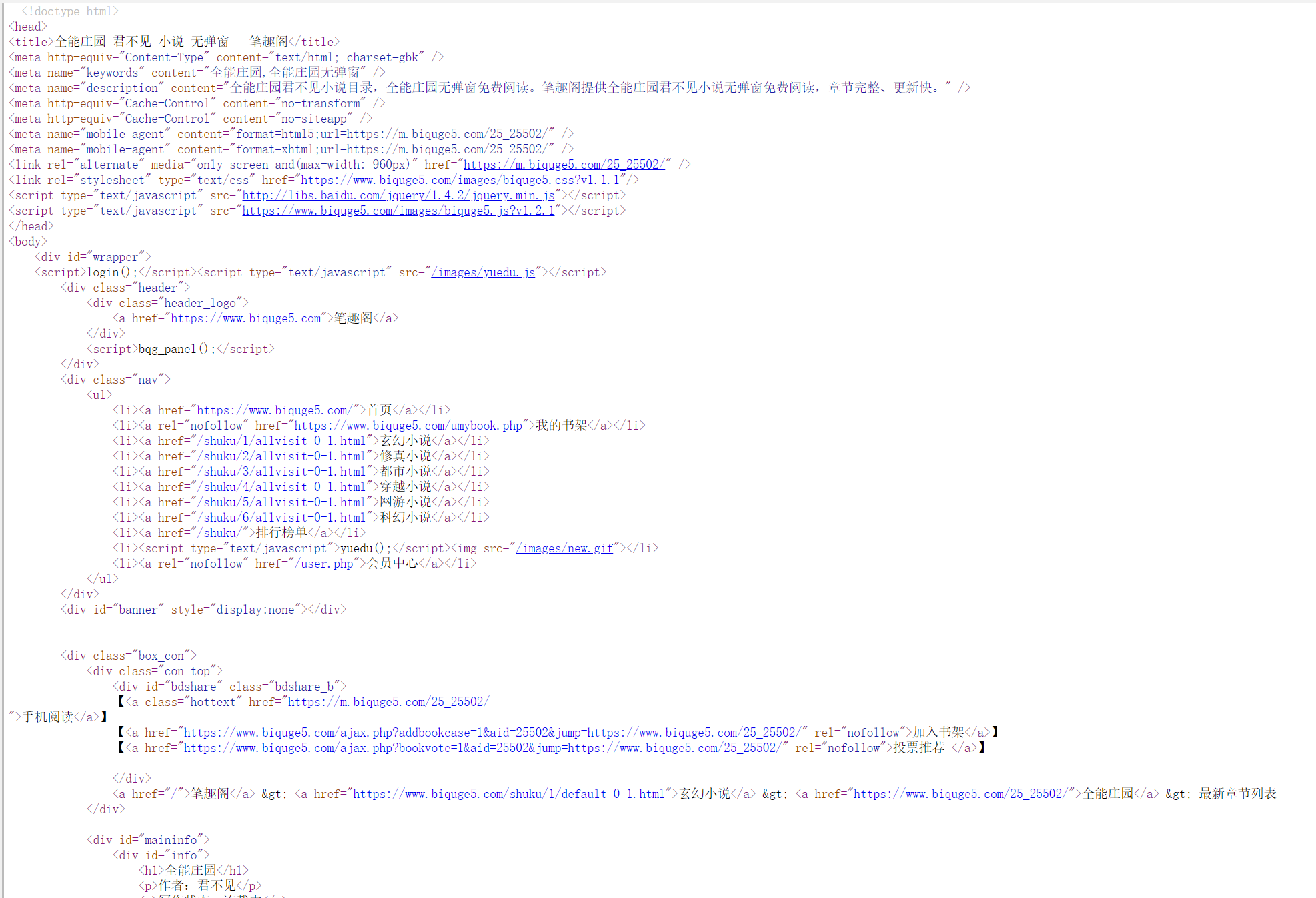
我们可以通过这个源码分析分析出一些东西:
1、找到小说的名称
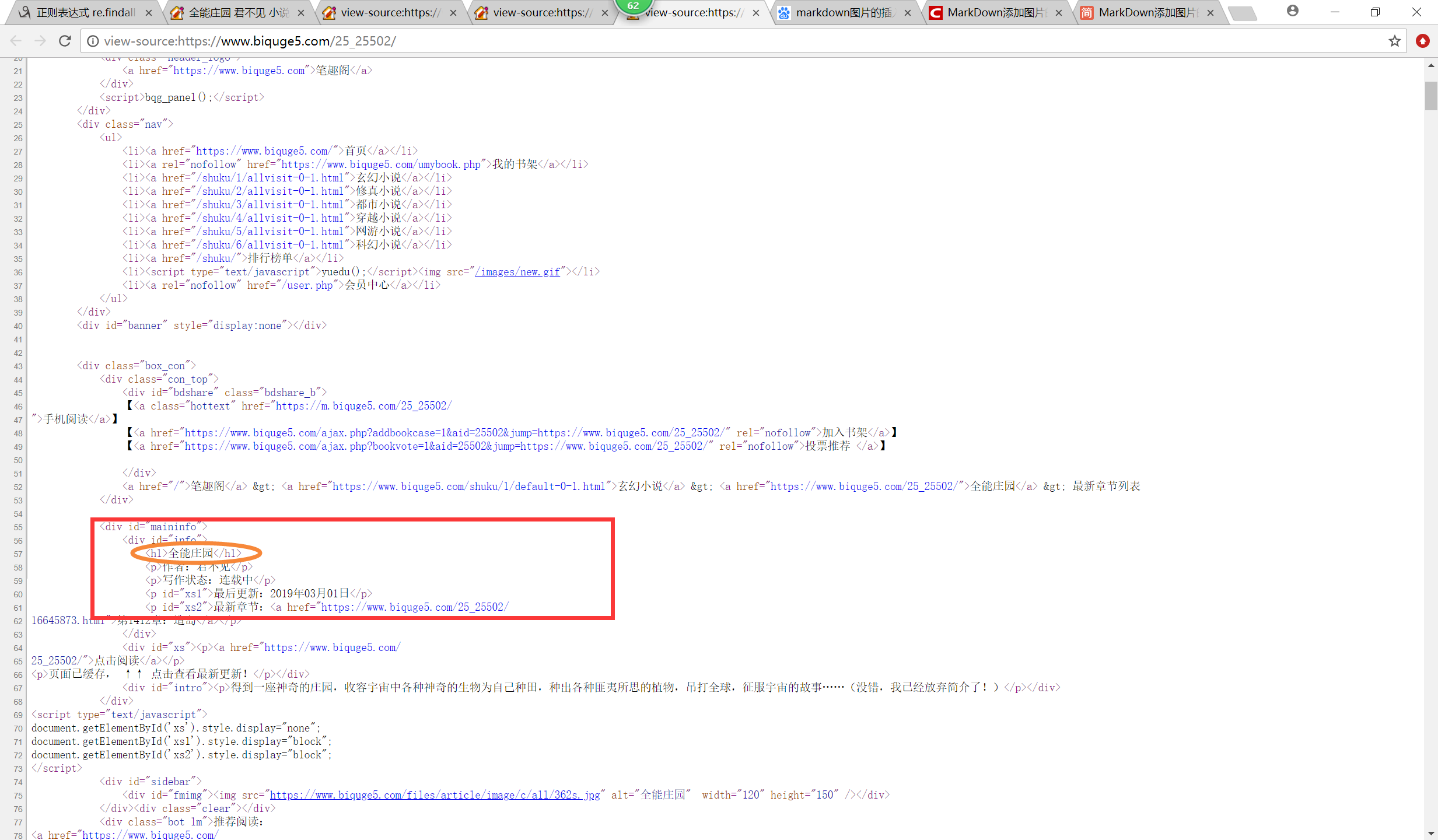
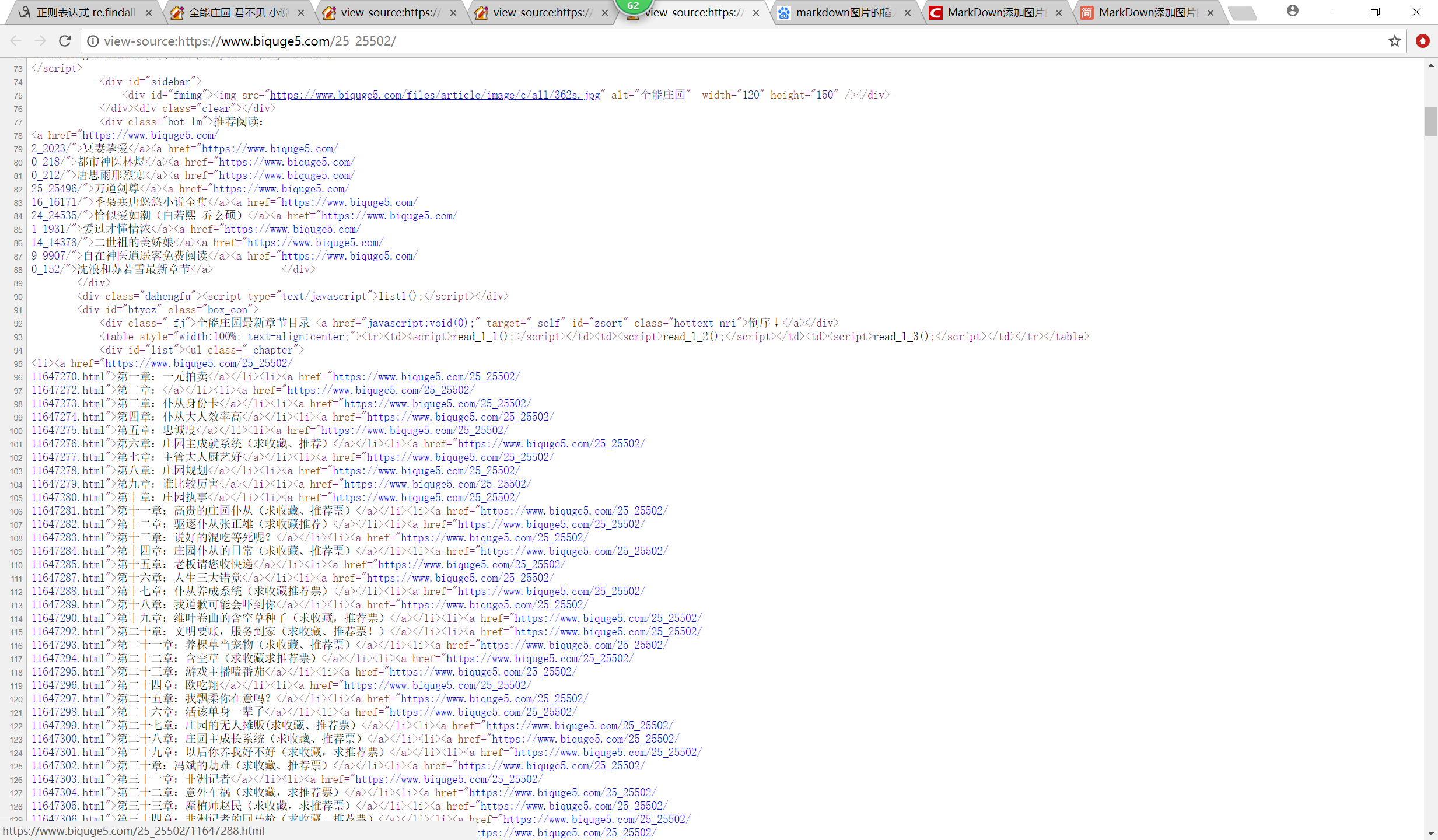
2、找到小说下面的具体的章节和链接(url):
3、通过url再进入具体的章节内容,然后再进入网页源代码(第一章为例):
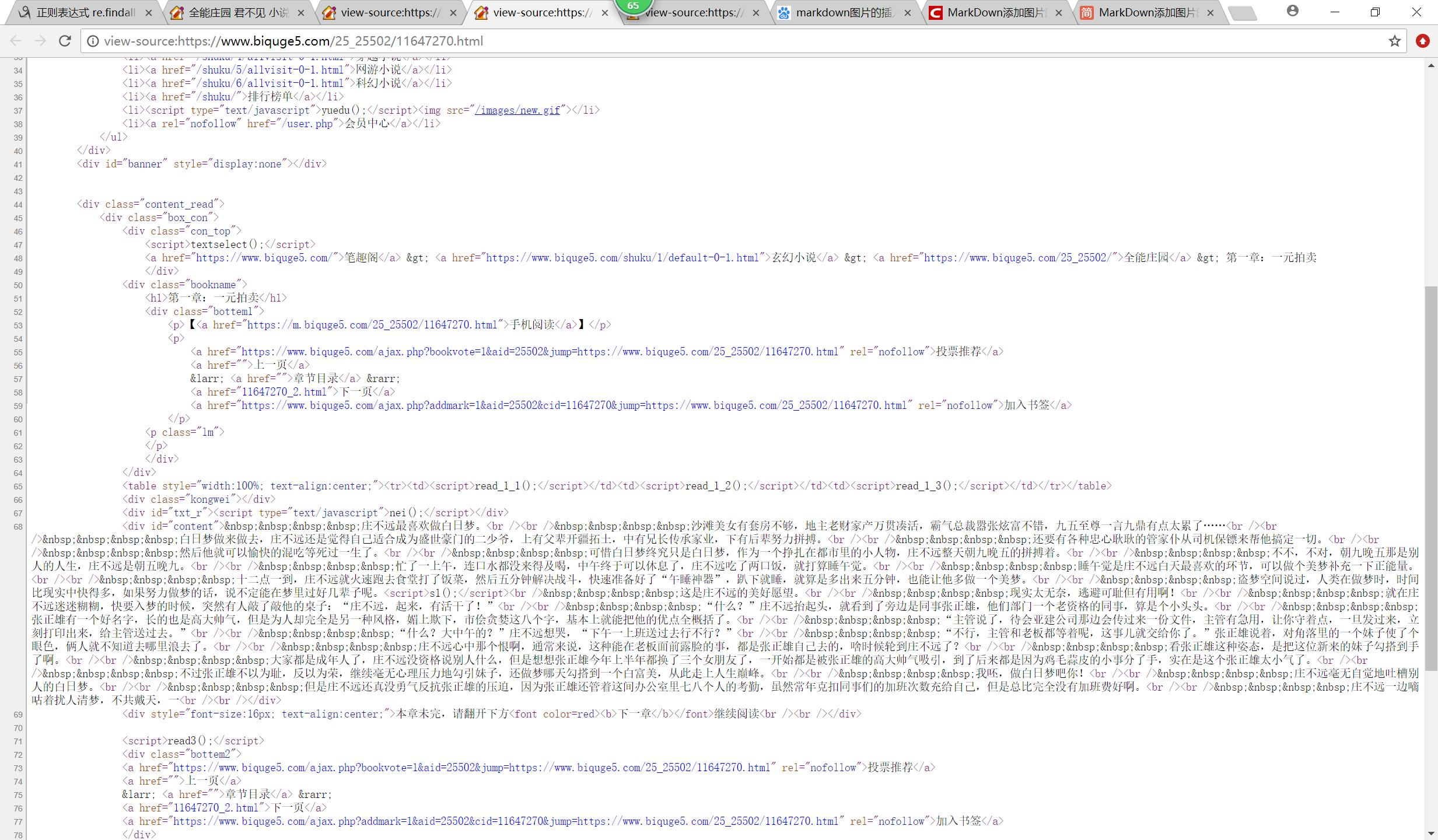
4、找到其中的正文内容就可以导出来了
当然网页的分析需要正则表达式
正则表达式
这里通过 re.findall() 来实现
1 | re.findall(p,string) |
这个需要库re
1 | import re |
re.findall ( ) 查找全部r标识代表后面是正则的语句
下面举一个小小的例子:
1 | import re |
得到结果:
1 | ['hello'] |
(.*?)
这个可以匹配所有字符(长度不限):
1 | import re |
得到结果:
1 | [' worl'] |
正则end
觉得菜鸟教程中的正则表达式写的挺好的,就不写了,偷懒以下。
代码实现
稍微正式一点了
请求头
爬别人的网站你就是模仿浏览器,模仿浏览器发送http请求,但是你需要一个请求头,表示是模仿请求的,不然可能会被封或者无法访问。(当然,很多网站加不加这个请求头是无所谓的)
我用的是chrome的:
1 | header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"} |
requests.get()
接下来才是正戏上场
利用requests.get()获得网页上的内容
1 | # 获得一个网址 |
获得章节url和章节名称
1 | chapter_info_list = re.findall(r'(.*?)">(.*?)</a></li><li>',html) |
重复上面的步骤
1 | for chapter_info in chapter_info_list: |
End
第一次爬虫,感觉还是有点有趣,但是不懂得地方还有很多。
本来是打算爬新笔趣阁的,但是新笔趣阁通过requests.get()得到的源码有失真,有一部分正文内容缺失了,估计做了特殊的处理,因此需要后续继续学习,像什么动态网页的爬取之类…………