SSFPN
论文地址:https://arxiv.org/abs/2206.07298
论文中项目地址:https://github.com/mohamedac29/S2-FPN/
自己实现的项目地址:https://github.com/llfzllfz/DL_Exercise/tree/main/SSFPN
模型纵览
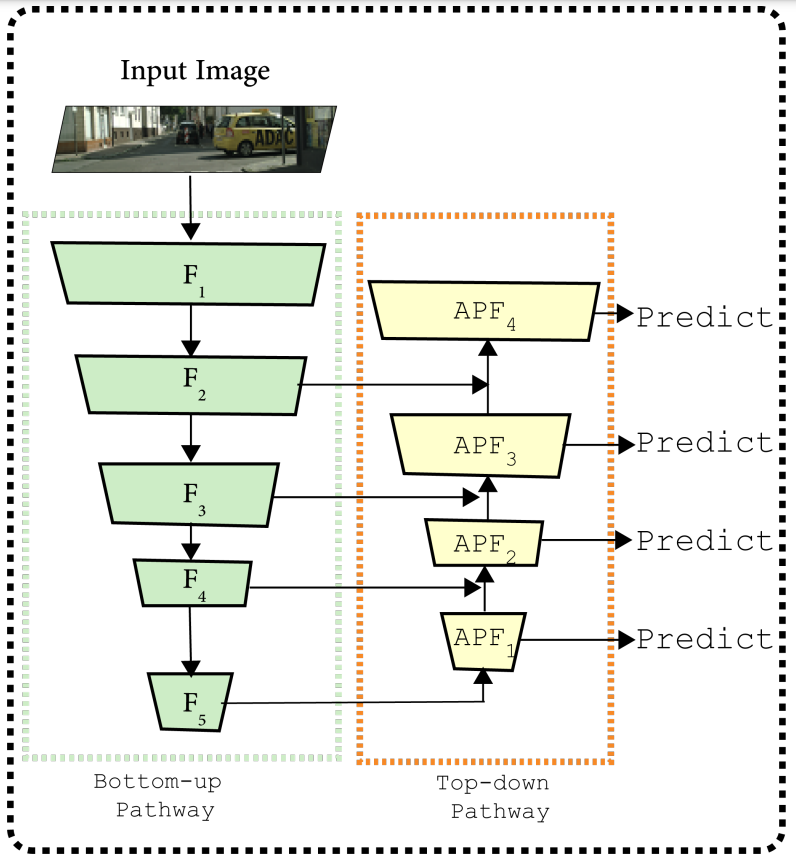
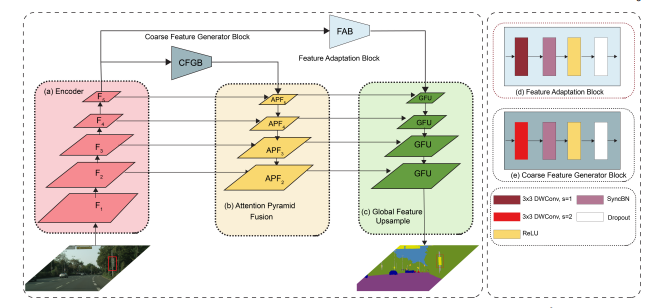
上面两个模型讲述了SSFPN的模型总体结构。
Overview
根据上面图片中的描述,就可以得到模型的总体结构,模型分为三个部分:
- 特征抽取或编码
- 注意力金字塔融合(APF)
- 全局特征上采样(GFU)
其中分别包括了CFGB,FAB,SSAM。
SSFPN采用resnet18或者resnet34作为基础的model,去掉其中的全局平均池化层以及softmax,根据基础模型的步长取出对应的特征。步长为2,4,8,16,32的情况下,得到F1,F2,F3,F4,F5。
在F5之后分别接两个模块:
- 粗糙特征生成块(CFGB)
- 包含一个步长为2的卷积层来生成粗糙特征,目的是为了APF做准备
- 特征适应块(FAB)
- 包含一个步长为1的卷积层来为GFU做准备
注意:APF中步长分别为4,8,16,32。
APF2,APF3,APF4,APF5是从上到下的特征生成,使用APF模块。
Code-SSFPN
1 | class SSFPN(nn.Module): |
比例感知注意力模块(SSAM)
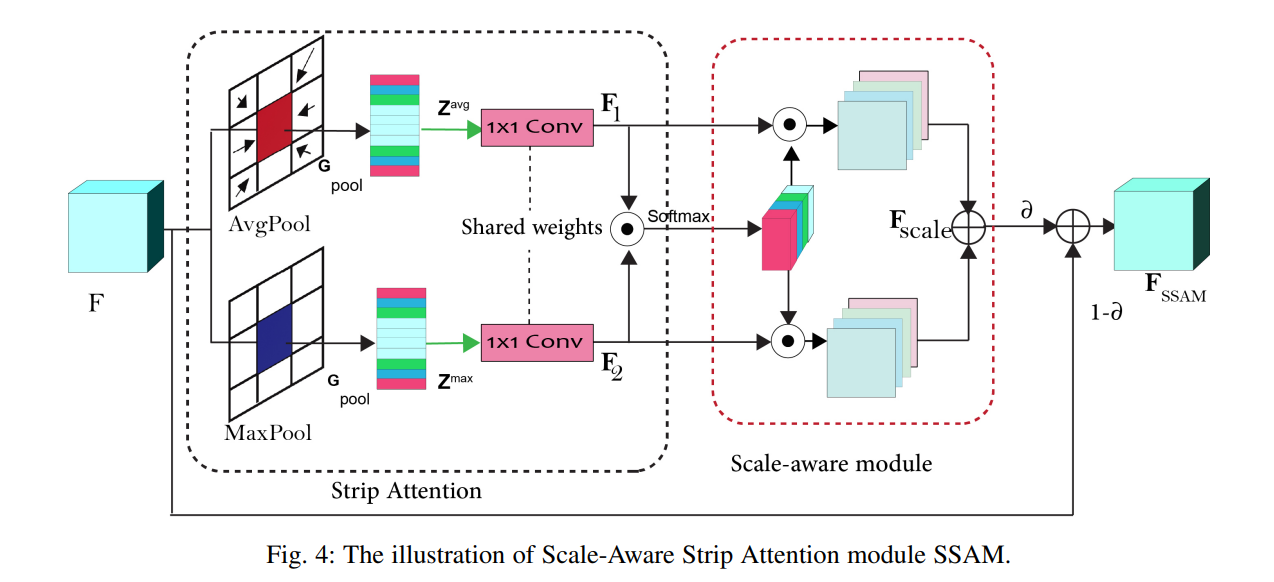
SSAM模块见上方图形,其目的是为了获得长范围的依赖关系以及减少计算资源的消耗。
首先用平均池化层(Avg Pool)和最大池化层(Max Pool)分别提取特征,然后过一个权重共享的1*1的卷积层得到F1和F2。
其中在平均池化和最大池化的时候是按照行进行池化,最后得到(C, H, 1)的size,但是在论文作者的实现中,采用的是按列池化,本项目采用的是按行池化。
利用F1和F2得到Attention部分,也就是A=F1⊙F2
然后Attention再过一个softmax
最后得到$F_{scale} = A ⊙ F_1 + A ⊙ F_2 $
SSAM的最后输出为$F_{SSAM} = \alpha F_{scale} + (1 - \alpha)F$
原作者在$F_{scale}$之后又过了一个卷积层,但是在论文中并没有看到相应的描述。
Code-SSAM
1 | class SSAM(nn.Module): |
注意力金字塔融合模块(APF)
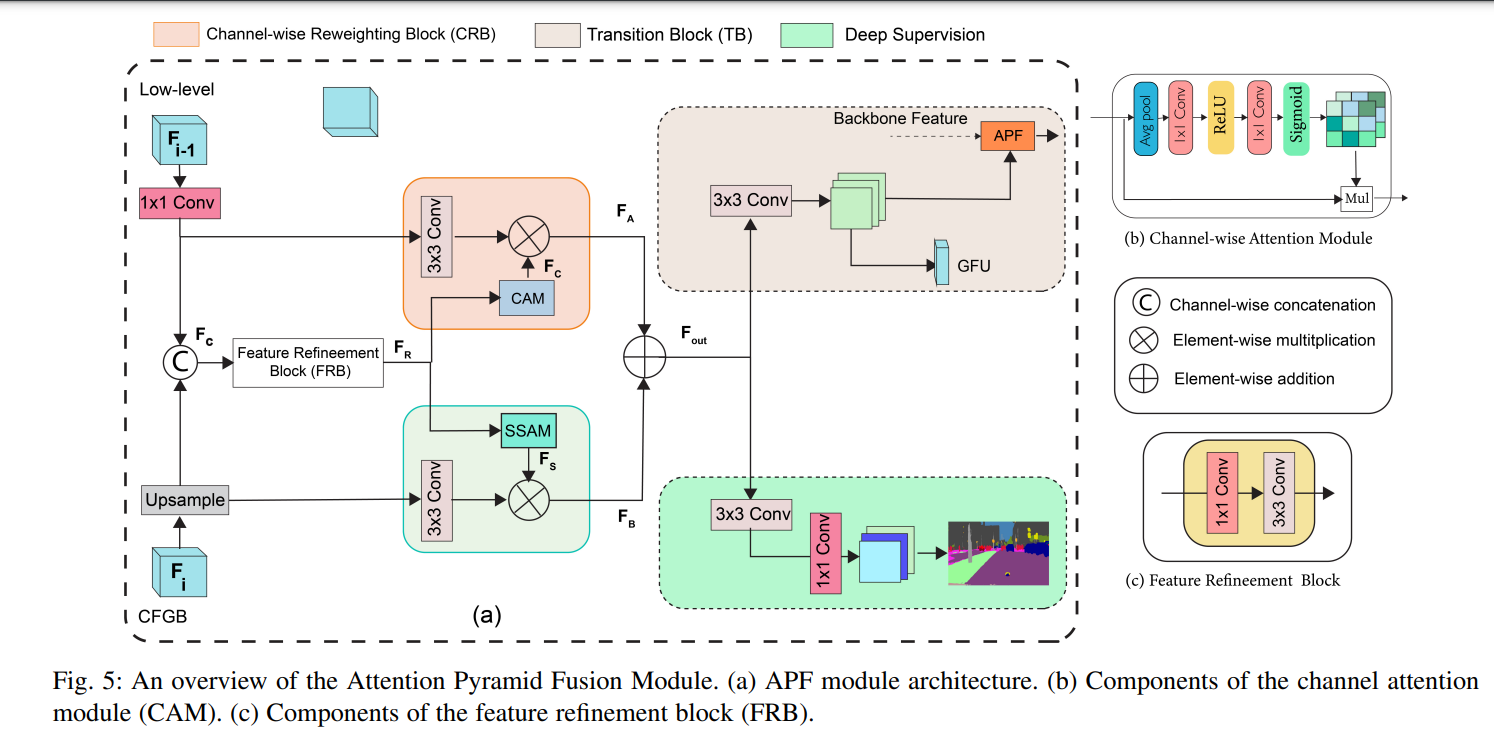
APF模块有两个输入,一个是顶层APF的输入($F_{i-1}$),一个是来自侧层F的输入($F_i$)
$F_{i-1 }$先通过一个带normalization和relu的1*1卷积层,$F_i$通过一个上采样层来适应$F_{ i-1 }$
然后再通过concat将这两个输出拼接起来得到$F_{concat}$,同时将这个输入到一个FRB中得到$F_{R}$
FRB里面包含了1*1和3*3的卷积层,都带着normalization和relu。
接下去,将$F_{ i-1 }$经过一个带normalization和relu的3*3的卷积层。
$F_{R}$经过一个CAM再与$F_{i -1}$相乘得到输出$F_{A}$
$F_{R}$经过一个SSAM与经过一个3*3卷积层的$F_{i}$相乘得到输出$F_{B}$
最后得到输出$F_{out} = F_{A} + F_{B}$
$F_{out}$之后接3*3的卷积层进入到相应的处理模块,例如pre和下一个APF以及相应的GFU
Code-CAM
1 | class CAM(nn.Module): |
Code-APF
1 | class APF(nn.Module): |
全局特征上采样(GFU)
在模型纵览中的第一张图片中,APF后面接的是Predict,但是在第二张图中,显示的是GFU,同时该模型会输出5个输出。
其中每个APF后各有一个输出,GFU后还有一个输出,做推理的时候用的是GFU后的输出。
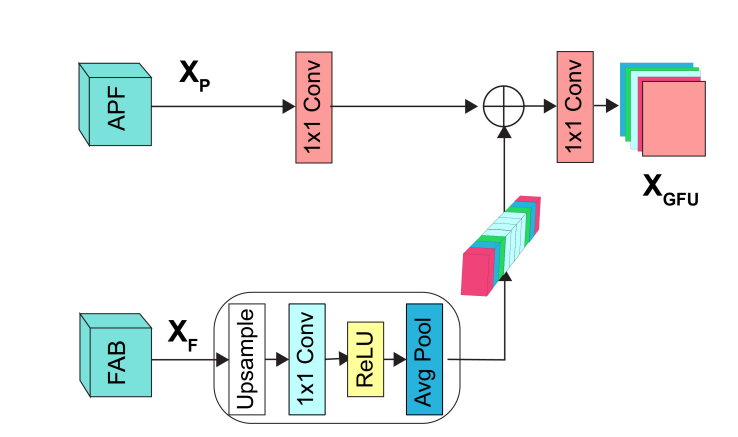
GFU的模型整理来说相对简单。
- FAB经过一个上采样,然后过一个1*1的卷积再做relu和平均池化得到$X_{F}$的输出
- APF经过一个1*1的卷积得到$X_P$的输出
- 最后得到$X_{GFU} = (f^1(X_F+ X_P))$,其中$f^1$表示经过一个1*1的卷积层
Code-GFU
1 | class GFU(nn.Module): |
Code-Conv_block
1 | class conv_block(nn.Module): |
实践
数据集:Baidu People segmentation dataset
数据集参考来源:https://blog.csdn.net/MOU_IT/article/details/82225505


第一张显示的是原图片,第二张显示的是分割后的图片。
因为受到机器限制以及数据集像素不统一的问题,因此统一resize成了(224, 224)的大小。
结果

这是根据config里面的参数train10轮得到的结果,并没有完全run完。
接下去利用val中得到的最好成绩的模型进行预测
以上左图为原图,右图为分割图

上面这幅图为模型预测的图,根据对比,可以发现,已经大部分相似了。
可以肯定,如果多训练一段时间,会得到更好的结果。